This article summarizes methods for jailbreaking LLM, focusing on techniques from the BEST-OF-N JAILBREAKING paper.总结了大模型越狱的方法,重点介绍了BEST-OF-N JAILBREAKING 论文和米斯特安全团队的Prompt越狱手册中的技术。
AI资讯|OpenAI为Responses API新增了包括远程MCP服务器支持、图像生成和代码解释器工具等功能
This article covers OpenAI's Responses API updates (MCP, image generation, code interpreter), Cline's Workflows and Rules, B站's Index-AniSora and Index-TTS models, the Awsome-Manus website, 砺算科技's GPU, and Q1 2025 China smartphone sales.文章介绍了OpenAI的API更新(MCP,Image Generation,Code解释器),Cline的工作流和规则,B站索引 - anisora和Index-TTS模型,Awsome-Manus网站,GPU和国内2025年Q1季度智能手机销量/市占率等数据。
终端AI利器:两款效率神器助你码力十足
介绍了两款可在终端中运行的AI工具:OpenAI Codex CLI 和 sigoden/aichat,方便开发者在终端中使用AI能力。
AI周报20250516-写了个MCP翻译工具
A weekly summary of interesting links and topics, including a MCP translation tool, DeepLX, education resources, automotive regulations, and GitHub acceleration.
使用阿里云快照快速复制系统环境,服务器始终显示'操作系统启动中'
本文介绍了如何使用阿里云快照快速复制系统环境,以及如何解决使用自定义镜像后服务器始终显示“操作系统启动中”的问题。This article describes how to use Alibaba Cloud snapshots to quickly replicate a system environment, and how to solve the problem of the server always displaying 'Operating system starting' after using a custom image.
Quickly Replicating System Environments Using Alibaba Cloud Snapshots; Server Constantly Displays 'Operating System Starting'
This article describes how to use Alibaba Cloud snapshots to quickly replicate a system environment, and how to solve the problem of the server always displaying 'Operating system starting' after using a custom image.
MCP 工具投毒实验
本文探讨 MCP 工具投毒实验及其安全影响。近日,MCP被发现存在工具投毒攻击(Tool Poisoning Attack,简称TPA)等风险,主要影响Cursor、Claude for Desktop等MCP客户端用户。工具投毒攻击的核心机制在于,攻击者可以在MCP代码注释中的工具描述里嵌入恶意指令,这些指令对用户不直接可见但对AI模型可见。这些隐藏指令可以操纵AI Agent执行未经授权的操作,例如读取敏感文件、泄露私密数据等。
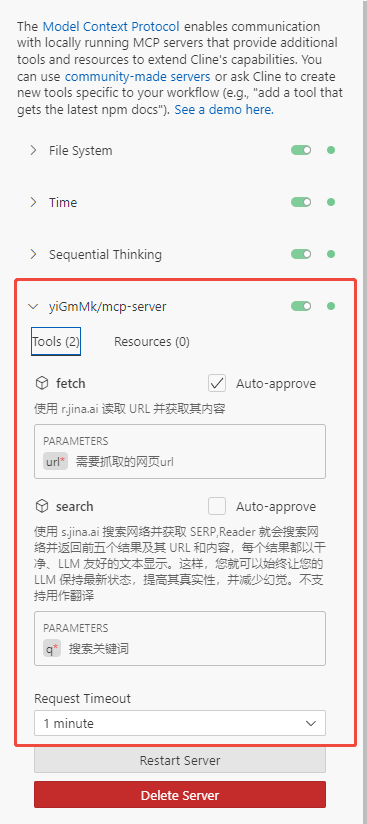
模型上下文协议(MCP)入门(5):动手写个mcp server
使用mcp官方的python-sdk写个mcp server,在cline中使用
代码
源码已开源,详见mcp-sever
目前提供2个工具,封装jina.ai的api实现
1 |
|
安装
使用uv安装,配置时有个需要注意的点,即配置代码运行目录,否则需要配置环境变量 VIRTUAL_ENV
优先使用下面这种配置方式
1 | { |
在cline中使用gemini-2.0-flash参考README文档就能完成安装mcp-server
效果
模型上下文协议(MCP)入门(3):精选MCP服务器
精选的优秀模型上下文协议 (MCP) 服务器列表。
什么是MCP?
MCP 是一种开放协议,通过标准化的服务器实现,使 AI 模型能够安全地与本地和远程资源进行交互。此列表重点关注可用于生产和实验性的 MCP 服务器,这些服务器通过文件访问、数据库连接、API 集成和其他上下文服务来扩展 AI 功能。
教程
社区
说明
- 🎖️ – 官方实现
- 编程语言
- 🐍 – Python 代码库
- 📇 – TypeScript 代码库
- 🏎️ – Go 代码库
- 🦀 – Rust 代码库
- #️⃣ - C# 代码库
- ☕ - Java 代码库
- 范围
- ☁️ - 云服务
- 🏠 - 本地服务
- 操作系统
- 🍎 – For macOS
- 🪟 – For Windows
[!NOTE]
关于本地 🏠 和云 ☁️ 的区别:
- 当 MCP 服务器与本地安装的软件通信时使用本地服务,例如控制 Chrome 浏览器。
- 当 MCP 服务器与远程 API 通信时使用网络服务,例如天气 API。
服务器实现
[!NOTE]
我们现在有一个与存储库同步的基于 Web 的目录。
- 📂 - 浏览器自动化
- 🎨 - 艺术与文化
- ☁️ - 云平台
- 🖥️ - 命令行
- 💬 - 社交
- 👤 - 数据平台
- 🗄️ - 数据库
- 🛠️ - 开发者工具
- 📂 - 文件系统
- 💰 - Finance & Fintech
- 🧠 - 知识与记忆
- 🗺️ - 位置服务
- 🎯 - 营销
- 📊 - 监测
- 🔎 - 搜索
- 🔒 - 安全
- 🚆 - 旅行与交通
- 🔄 - 版本控制
- 🛠️ - 其他工具和集成
📂 浏览器自动化
Web 内容访问和自动化功能。支持以 AI 友好格式搜索、抓取和处理 Web 内容。
- @blackwhite084/playwright-plus-python-mcp 🌐 - 使用 Playwright 进行浏览器自动化的 MCP 服务器,更适合llm
- @executeautomation/playwright-mcp-server 🌐⚡️ - 使用 Playwright 进行浏览器自动化和网页抓取的 MCP 服务器
- @automatalabs/mcp-server-playwright 🌐🖱️ - 使用 Playwright 实现浏览器自动化的 MCP 服务器
- @modelcontextprotocol/server-puppeteer 📇 🏠 - 用于网页抓取和交互的浏览器自动化
- @kimtaeyoon83/mcp-server-youtube-transcript 📇 ☁️ - 获取 YouTube 字幕和文字记录以供 AI 分析
- @recursechat/mcp-server-apple-shortcuts 📇 🏠 🍎 - MCP 服务器与 Apple Shortcuts 的集成
- kimtth/mcp-aoai-web-browsing 🐍 🏠 - 使用 Azure OpenAI 和 Playwright 的“最小”服务器/客户端 MCP 实现。
- @pskill9/web-search 📇 🏠 - 一个支持使用 Google 搜索结果进行免费网页搜索的 MCP 服务器,无需 API 密钥
🎨 艺术与文化
提供艺术收藏、文化遗产和博物馆数据库的访问与探索。让 AI 模型能够搜索和分析艺术文化内容。
- burningion/video-editing-mcp 📹🎬 - 从您的视频集合中添加、分析、搜索和生成视频剪辑
- r-huijts/rijksmuseum-mcp 📇 ☁️ - 荷兰国立博物馆 API 集成,支持艺术品搜索、详情查询和收藏品浏览
☁️ 云平台
云平台服务集成。实现与云基础设施和服务的管理和交互。
- Cloudflare MCP Server 🎖️ 📇 ☁️ - 与 Cloudflare 服务集成,包括 Workers、KV、R2 和 D1
- Kubernetes MCP Server - 🏎️ ☁️ 通过 MCP 操作 Kubernetes 集群
- @flux159/mcp-server-kubernetes - 📇 ☁️/🏠 使用 Typescript 实现 Kubernetes 集群中针对 pod、部署、服务的操作。
- johnneerdael/netskope-mcp 🔒 ☁️ - 提供对 Netskope Private Access 环境中所有组件的访问权限,包含详细的设置信息和 LLM 使用示例。
🖥️ Command Line
运行命令、捕获输出以及以其他方式与 shell 和命令行工具交互。
- ferrislucas/iterm-mcp 🖥️ 🛠️ 💬 - 一个为 iTerm 终端提供访问能力的 MCP 服务器。您可以执行命令,并就终端中看到的内容进行提问交互。
- g0t4/mcp-server-commands 📇 🏠 - 使用“run_command”和“run_script”工具运行任何命令。
- MladenSU/cli-mcp-server 🐍 🏠 - 具有安全执行和可定制安全策略的命令行界面
- tumf/mcp-shell-server 实现模型上下文协议 (MCP) 的安全 shell 命令执行服务器
💬 社交
与通讯平台集成,实现消息管理和渠道运营。使AI模型能够与团队沟通工具进行交互。
- zcaceres/gtasks-mcp - 📇 ☁️ - 用于管理 Google Tasks 的 MCP 服务器
- hannesrudolph/imessage-query-fastmcp-mcp-server 🐍 🏠 🍎 - MCP 服务器通过模型上下文协议 (MCP) 提供对 iMessage 数据库的安全访问,使 LLM 能够通过适当的电话号码验证和附件处理来查询和分析 iMessage 对话
- @modelcontextprotocol/server-slack 📇 ☁️ - 用于频道管理和消息传递的 Slack 工作区集成
- @modelcontextprotocol/server-bluesky 📇 ☁️ - Bluesky 实例集成,用于查询和交互
- MarkusPfundstein/mcp-gsuite - 🐍 ☁️ - 与 Gmail 和 Google 日历集成。
- adhikasp/mcp-twikit 🐍 ☁️ - 与 Twitter 搜索和时间线进行交互
- gotoolkits/wecombot - 🚀 ☁️ - MCP服务器 Tools 应用程序,用于向企业微信群机器人发送各种类型的消息。
- AbdelStark/nostr-mcp - 🌐 ☁️ - Nostr MCP 服务器,支持与 Nostr 交互,可发布笔记等功能。
- sawa-zen/vrchat-mcp - 📇 🏠 这是一个与VRChat API交互的MCP服务器。您可以获取VRChat的好友、世界、化身等信息。
👤 数据平台
提供对客户数据平台内客户资料的访问
- sergehuber/inoyu-mcp-unomi-server 📇 ☁️ - MCP 服务器用于访问和更新 Apache Unomi CDP 服务器上的配置文件。
- OpenDataMCP/OpenDataMCP 🐍☁️ - 使用模型上下文协议将任何开放数据连接到任何 LLM。
- tinybirdco/mcp-tinybird 🐍☁️ - MCP 服务器可从任何 MCP 客户端与 Tinybird Workspace 进行交互。
- @iaptic/mcp-server-iaptic 🎖️ 📇 ☁️ - 连接 iaptic 平台,让您轻松查询客户购买记录、交易数据以及应用营收统计信息。
🗄️ 数据库
具有模式检查功能的安全数据库访问。支持使用可配置的安全控制(包括只读访问)查询和分析数据。
- cr7258/elasticsearch-mcp-server 🐍 🏠 - 集成 Elasticsearch 的 MCP 服务器实现
- domdomegg/airtable-mcp-server 📇 🏠 - Airtable 数据库集成,具有架构检查、读写功能
- LucasHild/mcp-server-bigquery 🐍 ☁️ - BigQuery 数据库集成了架构检查和查询功能
- c4pt0r/mcp-server-tidb 🐍 ☁️ - TiDB 数据库集成,包括表结构的建立 DDL 和 SQL 的执行
- ergut/mcp-bigquery-server 📇 ☁️ - Google BigQuery 集成的服务器实现,可实现直接 BigQuery 数据库访问和查询功能
- ClickHouse/mcp-clickhouse 🐍 ☁️ - 集成 Apache Kafka 和 Timeplus。可以获取Kafka中的最新数据,并通过 Timeplus 来 SQL 查询。
- jovezhong/mcp-timeplus 🐍 ☁️ - MCP server for Apache Kafka and Timeplus. Able to list Kafka topics, poll Kafka messages, save Kafka data locally and query streaming data with SQL via Timeplus
- @fireproof-storage/mcp-database-server 📇 ☁️ - Fireproof 分布式账本数据库,支持多用户数据同步
- designcomputer/mysql_mcp_server 🐍 🏠 - MySQL 数据库集成可配置的访问控制、模式检查和全面的安全指南
- f4ww4z/mcp-mysql-server 🐍 🏠 - 基于 Node.js 的 MySQL 数据库集成,提供安全的 MySQL 数据库操作
- @modelcontextprotocol/server-postgres 📇 🏠 - PostgreSQL 数据库集成了模式检查和查询功能
- @modelcontextprotocol/server-sqlite 🐍 🏠 - 具有内置分析功能的 SQLite 数据库操作
- @joshuarileydev/supabase-mcp-server - Supabase MCP 服务器用于管理和创建 Supabase 中的项目和组织
- ktanaka101/mcp-server-duckdb 🐍 🏠 - DuckDB 数据库集成了模式检查和查询功能
- QuantGeekDev/mongo-mcp 📇 🏠 - MongoDB 集成使 LLM 能够直接与数据库交互。
- tinybirdco/mcp-tinybird 🐍 ☁️ - Tinybird 集成查询和 API 功能
- kiliczsh/mcp-mongo-server 📇 🏠 - MongoDB 的模型上下文协议服务器
- KashiwaByte/vikingdb-mcp-server 🐍 ☁️ - VikingDB 数据库集成了collection和index的基本信息介绍,并提供向量存储和查询的功能.
- neo4j-contrib/mcp-neo4j 🐍 🏠 - Neo4j 的模型上下文协议
- isaacwasserman/mcp-snowflake-server 🐍 ☁️ - Snowflake 集成实现,支持读取和(可选)写入操作,并具备洞察跟踪功能
- hannesrudolph/sqlite-explorer-fastmcp-mcp-server 🐍 🏠 - 一个 MCP 服务器,通过模型上下文协议 (MCP) 提供对 SQLite 数据库的安全只读访问。该服务器是使用 FastMCP 框架构建的,它使 LLM 能够探索和查询具有内置安全功能和查询验证的 SQLite 数据库。
- sirmews/mcp-pinecone 🐍 ☁️ - Pinecone 与矢量搜索功能的集成
- runekaagaard/mcp-alchemy 🐍 🏠 - 基于SQLAlchemy的通用数据库集成,支持PostgreSQL、MySQL、MariaDB、SQLite、Oracle、MS SQL Server等众多数据库。具有架构和关系检查以及大型数据集分析功能。
- GreptimeTeam/greptimedb-mcp-server 🐍 🏠 - 查询 GreptimeDB 的 MCP 服务。
💻 开发者工具
增强开发工作流程和环境管理的工具和集成。
- QuantGeekDev/docker-mcp 🏎️ 🏠 - 通过 MCP 进行 Docker 容器管理和操作
- zcaceres/fetch-mcp 📇 🏠 - 一个灵活获取 JSON、文本和 HTML 数据的 MCP 服务器
- r-huijts/xcode-mcp-server 📇 🏠 🍎 - Xcode 集成,支持项目管理、文件操作和构建自动化
- snaggle-ai/openapi-mcp-server 🏎️ 🏠 - 使用开放 API 规范 (v3) 连接任何 HTTP/REST API 服务器
- jetbrains/mcpProxy 🎖️ 📇 🏠 - 连接到 JetBrains IDE
- tumf/mcp-text-editor 🐍 🏠 - 面向行的文本文件编辑器。针对 LLM 工具进行了优化,具有高效的部分文件访问功能,可最大限度地减少令牌使用量。
- @joshuarileydev/simulator-mcp-server 📇 🏠 - 用于控制 iOS 模拟器的 MCP 服务器
- @joshuarileydev/app-store-connect-mcp-server 📇 🏠 - 一个 MCP 服务器,用于与 iOS 开发者的 App Store Connect API 进行通信
- @sammcj/mcp-package-version 📦 🏠 - MCP 服务器可帮助 LLM 在编写代码时建议最新的稳定软件包版本。
- delano/postman-mcp-server 📇 ☁️ - 与 Postman API 进行交互
- vivekVells/mcp-pandoc 🗄️ 🚀 - 基于 Pandoc 的 MCP 服务器,支持 Markdown、HTML、PDF、DOCX(.docx)、csv 等格式之间的无缝转换
- pskill9/website-downloader 🗄️ 🚀 - 这个 MCP 服务器提供了使用 wget 下载完整网站的工具,可保留网站结构并转换链接以支持本地访问
- j4c0bs/mcp-server-sql-analyzer 🐍 - 基于 SQLGlot 的 MCP 服务器,提供 SQL 分析、代码检查和方言转换功能
🧮 数据科学工具
旨在简化数据探索、分析和增强数据科学工作流程的集成和工具。
- @reading-plus-ai/mcp-server-data-exploration 🐍 ☁️ - 支持对基于 .csv 的数据集进行自主数据探索,以最小的成本提供智能见解。
- zcaceres/markdownify-mcp 📇 🏠 - 一个 MCP 服务器,可将几乎任何文件或网络内容转换为 Markdown
📂 文件系统
提供对本地文件系统的直接访问,并具有可配置的权限。使 AI 模型能够读取、写入和管理指定目录中的文件。
- @modelcontextprotocol/server-filesystem 📇 🏠 - 直接访问本地文件系统。
- @modelcontextprotocol/server-google-drive 📇 ☁️ - Google Drive 集成,用于列出、阅读和搜索文件
- hmk/box-mcp-server 📇 ☁️ - Box 集成,支持文件列表、阅读和搜索功能
- mark3labs/mcp-filesystem-server 🏎️ 🏠 - 用于本地文件系统访问的 Golang 实现。
- mamertofabian/mcp-everything-search 🐍 🏠 🪟 - 使用 Everything SDK 实现的快速 Windows 文件搜索
- cyberchitta/llm-context.py 🐍 🏠 - 通过 MCP 或剪贴板与 LLM 共享代码上下文
- Xuanwo/mcp-server-opendal 🐍 🏠 ☁️ - 使用 Apache OpenDAL™ 访问任何存储
💰 金融 & 金融科技
金融数据访问和加密货币市场信息。支持查询实时市场数据、加密货币价格和财务分析。
- QuantGeekDev/coincap-mcp 📇 ☁️ - 使用 CoinCap 的公共 API 集成实时加密货币市场数据,无需 API 密钥即可访问加密货币价格和市场信息
- anjor/coinmarket-mcp-server 🐍 ☁️ - Coinmarket API 集成以获取加密货币列表和报价
- berlinbra/alpha-vantage-mcp 🐍 ☁️ - Alpha Vantage API 集成,用于获取股票和加密货币信息
- ferdousbhai/tasty-agent 🐍 ☁️ - Tastyworks API 集成,用于管理 Tastytrade 平台的交易活动
🧠 知识与记忆
使用知识图谱结构的持久内存存储。使 AI 模型能够跨会话维护和查询结构化信息。
- @modelcontextprotocol/server-memory 📇 🏠 - 基于知识图谱的长期记忆系统用于维护上下文
- /CheMiguel23/MemoryMesh 📇 🏠 - 增强基于图形的记忆,重点关注 AI 角色扮演和故事生成
- /topoteretes/cognee 📇 🏠 - AI应用程序和Agent的内存管理器使用各种图存储和向量存储,并允许从 30 多个数据源提取数据
- @hannesrudolph/mcp-ragdocs 🐍 🏠 - MCP 服务器实现提供了通过矢量搜索检索和处理文档的工具,使 AI 助手能够利用相关文档上下文来增强其响应能力
- @kaliaboi/mcp-zotero 📇 ☁️ - 为 LLM 提供的连接器,用于操作 Zotero Cloud 上的文献集合和资源
🗺️ 位置服务
地理和基于位置的服务集成。支持访问地图数据、方向和位置信息。
- @modelcontextprotocol/server-google-maps 📇 ☁️ - Google 地图集成,提供位置服务、路线规划和地点详细信息
- SecretiveShell/MCP-timeserver 🐍 🏠 - 访问任意时区的时间并获取当前本地时间
- webcoderz/MCP-Geo 🐍 🏠 - 支持 nominatim、ArcGIS、Bing 的地理编码 MCP 服务器
- @briandconnelly/mcp-server-ipinfo 🐍 ☁️ - 使用 IPInfo API 获取 IP 地址的地理位置和网络信息
🎯 营销
用于创建和编辑营销内容、处理网页元数据、产品定位和编辑指南的工具。
- Open Strategy Partners Marketing Tools 🐍 🏠 - Open Strategy Partners 提供的营销工具套件,包含写作风格指南、编辑规范和产品营销价值图谱创建工具
📊 监测
访问和分析应用程序监控数据。使 AI 模型能够审查错误报告和性能指标。
- @modelcontextprotocol/server-sentry 🐍 ☁️ - Sentry.io 集成用于错误跟踪和性能监控
- @modelcontextprotocol/server-raygun 📇 ☁️ - Raygun API V3 集成用于崩溃报告和真实用户监控
- metoro-io/metoro-mcp-server 🎖️ 🏎️ ☁️ - 查询并与 Metoro 监控的 kubernetes 环境交互
- grafana/mcp-grafana 🎖️ 🐍 🏠 ☁️ - 在 Grafana 实例中搜索仪表盘、调查事件并查询数据源
🔎 搜索
- @modelcontextprotocol/server-brave-search 📇 ☁️ - 使用 Brave 的搜索 API 实现网页搜索功能
- @angheljf/nyt 📇 ☁️ - 使用 NYTimes API 搜索文章
- @modelcontextprotocol/server-fetch 🐍 🏠 ☁️ - 高效获取和处理网页内容,供 AI 使用
- ac3xx/mcp-servers-kagi 📇 ☁️ - Kagi 搜索 API 集成
- exa-labs/exa-mcp-server 🎖️ 📇 ☁️ – 模型上下文协议 (MCP) 服务器让 Claude 等 AI 助手可以使用 Exa AI Search API 进行网络搜索。此设置允许 AI 模型以安全且可控的方式获取实时网络信息。
- fatwang2/search1api-mcp 📇 ☁️ - 通过 search1api 搜索(需要付费 API 密钥)
- Tomatio13/mcp-server-tavily ☁️ 🐍 – Tavily AI 搜索 API
- kshern/mcp-tavily ☁️ 📇 – Tavily AI 搜索 API
- blazickjp/arxiv-mcp-server ☁️ 🐍 - 搜索 ArXiv 研究论文
- mzxrai/mcp-webresearch 🔍📚 - 在 Google 上搜索并对任何主题进行深度研究
- andybrandt/mcp-simple-arxiv - 🐍 ☁️ MCP for LLM 用于搜索和阅读 arXiv 上的论文)
- andybrandt/mcp-simple-pubmed - 🐍 ☁️ MCP 用于搜索和阅读 PubMed 中的医学/生命科学论文。
- apify/mcp-server-rag-web-browser 📇 ☁️ - 一个用于 Apify 的 RAG Web 浏览器 Actor 的 MCP 服务器,可以执行网页搜索、抓取 URL,并以 Markdown 格式返回内容。
- SecretiveShell/MCP-searxng 🐍 🏠 - 用于连接到 searXNG 实例的 MCP 服务器
- Bigsy/Clojars-MCP-Server 📇 ☁️ - Clojars MCP 服务器,提供 Clojure 库的最新依赖信息
- Ihor-Sokoliuk/MCP-SearXNG 📇 🏠/☁️ - SearXNG 的模型上下文协议服务器
- erithwik/mcp-hn 🐍 ☁️ - 一个用于搜索 Hacker News、获取热门故事等的 MCP 服务器。
- chanmeng/google-news-mcp-server 📇 ☁️ - Google News 集成,具有自动主题分类、多语言支持,以及通过 SerpAPI 提供的标题、故事和相关主题的综合搜索功能。
- devflowinc/trieve 🎖️📇☁️🏠 - 通过 Trieve 爬取、嵌入、分块、搜索和检索数据集中的信息
🔒 安全
- dnstwist MCP Server 📇🪟☁️ - dnstwist 的 MCP 服务器,这是一个强大的 DNS 模糊测试工具,可帮助检测域名抢注、钓鱼和企业窃密行为
- Maigret MCP Server 📇 ☁️ - maigret 的 MCP 服务器,maigret 是一款强大的 OSINT 工具,可从各种公共来源收集用户帐户信息。此服务器提供用于在社交网络中搜索用户名和分析 URL 的工具。
- Shodan MCP Server 📇 ☁️ - MCP 服务器用于查询 Shodan API 和 Shodan CVEDB。此服务器提供 IP 查找、设备搜索、DNS 查找、漏洞查询、CPE 查找等工具。
- VirusTotal MCP Server 📇 ☁️ - 用于查询 VirusTotal API 的 MCP 服务器。此服务器提供用于扫描 URL、分析文件哈希和检索 IP 地址报告的工具。
- ORKL MCP Server 📇🛡️☁️ - 用于查询 ORKL API 的 MCP 服务器。此服务器提供获取威胁报告、分析威胁行为者和检索威胁情报来源的工具。
- Security Audit MCP Server 📇🛡️☁️ 一个强大的 MCP (模型上下文协议) 服务器,审计 npm 包依赖项的安全漏洞。内置远程 npm 注册表集成,以进行实时安全检查。
🚆 旅行与交通
访问旅行和交通信息。可以查询时刻表、路线和实时旅行数据。
- NS Travel Information MCP Server 📇 ☁️ - 了解荷兰铁路 (NS) 的旅行信息、时刻表和实时更新
🔄 版本控制
与 Git 存储库和版本控制平台交互。通过标准化 API 实现存储库管理、代码分析、拉取请求处理、问题跟踪和其他版本控制操作。
- @modelcontextprotocol/server-github 📇 ☁️ - GitHub API集成用于仓库管理、PR、问题等
- @modelcontextprotocol/server-gitlab 📇 ☁️ 🏠 - GitLab平台集成用于项目管理和CI/CD操作
- @modelcontextprotocol/server-git 🐍 🏠 - 直接的Git仓库操作,包括读取、搜索和分析本地仓库
- adhikasp/mcp-git-ingest 🐍 🏠 - 使用 LLM 阅读和分析 GitHub 存储库
🛠️ 其他工具和集成
- apify/actors-mcp-server 📇 ☁️ - 使用超过 3,000 个预构建的云工具(称为 Actors)从网站、电商、社交媒体、搜索引擎、地图等提取数据。
- ivo-toby/contentful-mcp 📇 🏠 - 更新、创建、删除 Contentful Space 中的内容、内容模型和资产
- mzxrai/mcp-openai 📇 ☁️ - 与 OpenAI 最智能的模型聊天
- mrjoshuak/godoc-mcp 🏎️ 🏠 - 高效的 Go 文档服务器,让 AI 助手可以智能访问包文档和类型,而无需阅读整个源文件
- pierrebrunelle/mcp-server-openai 🐍 ☁️ - 直接从Claude查询OpenAI模型,使用MCP协议
- @modelcontextprotocol/server-everything 📇 🏠 - MCP服务器,涵盖MCP协议的所有功能
- baba786/phabricator-mcp-server 🐍 ☁️ - 与Phabricator API交互
- MarkusPfundstein/mcp-obsidian 🐍 ☁️ 🏠 - 通过REST API与Obsidian交互
- calclavia/mcp-obsidian 📇 🏠 - 这是一个连接器,允许Claude Desktop(或任何MCP兼容应用程序)读取和搜索包含Markdown笔记的目录(如Obsidian库)。
- anaisbetts/mcp-youtube 📇 ☁️ - 获取YouTube字幕
- danhilse/notion_mcp 🐍 ☁️ - 与Notion API集成,管理个人待办事项列表
- rusiaaman/wcgw 🐍 🏠 - 自动化shell执行、计算机控制和编码代理。(Mac)
- reeeeemo/ancestry-mcp 🐍 🏠 - 允许AI读取.ged文件和基因数据
- sirmews/apple-notes-mcp 🐍 🏠 - 允许AI读取本地Apple Notes数据库(仅限macOS)
- anjor/coinmarket-mcp-server 🐍 🏠 - Coinmarket API集成,用于获取加密货币列表和报价
- suekou/mcp-notion-server 📇 🏠 - 与Notion API交互
- amidabuddha/unichat-mcp-server 🐍/📇 ☁️ - 使用MCP协议通过工具或预定义的提示发送请求给OpenAI、MistralAI、Anthropic、xAI或Google AI。需要供应商API密钥
- evalstate/mcp-miro 📇 ☁️ - 访问 MIRO 白板,批量创建和读取项目。需要 REST API 的 OAUTH 密钥。
- KS-GEN-AI/jira-mcp-server 📇 ☁️ 🍎 🪟 - 通过 JQL 和 API 读取 Jira 数据,并执行创建和编辑工单的请求
- KS-GEN-AI/confluence-mcp-server 📇 ☁️ 🍎 🪟 - 通过 CQL 获取 Confluence 数据并阅读页面
- sooperset/mcp-atlassian 🐍 ☁️ - Confluence工作区的自然语言搜索和内容访问
- pyroprompts/any-chat-completions-mcp - 与任何其他OpenAI SDK兼容的聊天完成API对话,例如Perplexity、Groq、xAI等
- anaisbetts/mcp-installer 🐍 🏠 - 一个MCP服务器,可以为您安装其他MCP服务器
- tanigami/mcp-server-perplexity 🐍 ☁️ - 与 Perplexity API 交互。
- future-audiences/wikimedia-enterprise-model-context-protocol 🐍 ☁️ - 维基百科文章查找 API
- andybrandt/mcp-simple-timeserver 🐍 🏠☁️ - MCP 服务器允许检查客户端计算机上的本地时间或 NTP 服务器上的当前 UTC 时间
- andybrandt/mcp-simple-openai-assistant - 🐍 ☁️ MCP 与 OpenAI 助手对话(Claude 可以使用任何 GPT 模型作为他的助手)
- @llmindset/mcp-hfspace 📇 ☁️ - 直接从 Claude 使用 HuggingFace Spaces。使用开源图像生成、聊天、视觉任务等。支持图像、音频和文本上传/下载。
- zueai/mcp-manager 📇 ☁️ - 简单的 Web UI 用于安装和管理 Claude 桌面应用程序的 MCP 服务器。
- wong2/mcp-cli 📇 🏠 - 用于测试 MCP 服务器的 CLI 工具
- isaacwasserman/mcp-vegalite-server 🐍 🏠 - 使用 VegaLite 格式和渲染器从获取的数据生成可视化效果。
- tevonsb/homeassistant-mcp 📇 🏠 - 访问家庭助理数据和控制设备(灯、开关、恒温器等)。
- allenporter/mcp-server-home-assistant 🐍 🏠 - 通过模型上下文协议服务器暴露所有 Home Assistant 语音意图,实现智能家居控制
- nguyenvanduocit/all-in-one-model-context-protocol 🏎️ 🏠 - 一些对开发人员有用的工具。
- @joshuarileydev/mac-apps-launcher-mcp-server 📇 🏠 - 用于列出和启动 MacOS 上的应用程序的 MCP 服务器
- ZeparHyfar/mcp-datetime - MCP 服务器提供多种格式的日期和时间函数
- apinetwork/piapi-mcp-server 📇 ☁️ PiAPI MCP服务器使用户能够直接从Claude或其他MCP兼容应用程序中使用Midjourney/Flux/Kling/Hunyuan/Udio/Trellis生成媒体内容。
- gotoolkits/DifyWorkflow - 🚀 ☁️ MCP 服务器 Tools 实现查询与执行 Dify AI 平台上自定义的工作流
- @pskill9/hn-server - 📇 ☁️ 解析 news.ycombinator.com(Hacker News)的 HTML 内容,为不同类型的故事(热门、最新、问答、展示、工作)提供结构化数据
- @mediar-ai/screenpipe - 🎖️ 🦀 🏠 🍎 本地优先的系统,支持屏幕/音频捕获并带有时间戳索引、SQL/嵌入存储、语义搜索、LLM 驱动的历史分析和事件触发动作 - 通过 NextJS 插件生态系统实现构建上下文感知的 AI 代理
- akseyh/bear-mcp-server - 允许 AI 读取您的 Bear Notes(仅支持 macOS)
- ws-mcp - 使用 WebSocket 包装 MCP 服务器(用于 kitbitz)
- AbdelStark/bitcoin-mcp - ₿ 一个模型上下文协议(MCP)服务器,使 AI 模型能够与比特币交互,允许它们生成密钥、验证地址、解码交易、查询区块链等
- kj455/mcp-kibela - 📇 ☁️ Kibela 与 MCP 的集成
- @awkoy/replicate-flux-mcp 📇 ☁️ - 通过Replicate API提供图像生成功能。
框架
- FastMCP 🐍 - 用于在 Python 中构建 MCP 服务器的高级框架
- FastMCP 📇 - 用于在 TypeScript 中构建 MCP 服务器的高级框架
- Foxy Contexts 🏎️ - 用于以声明方式编写 MCP 服务器的 Golang 库,包含功能测试
- Genkit MCP 📇 – 提供Genkit与模型上下文协议(MCP)之间的集成。
- LiteMCP ⚡️ - 用于在 JavaScript/TypeScript 中构建 MCP 服务器的高级框架
- mark3labs/mcp-go 🏎️ - 用于构建MCP服务器和客户端的Golang SDK。
- mcp-framework - ⚡️ 用于构建 MCP 服务器的快速而优雅的 TypeScript 框架
- mcp-proxy 📇 - 用于使用
stdio传输的 MCP 服务器的 TypeScript SSE 代理 - mcp-rs-template 🦀 - Rust的MCP CLI服务器模板
- metoro-io/mcp-golang 🏎️ - 用于构建 MCP 服务器的 Golang 框架,专注于类型安全。
- rectalogic/langchain-mcp 🐍 - 提供LangChain中MCP工具调用支持,允许将MCP工具集成到LangChain工作流中。
- salty-flower/ModelContextProtocol.NET #️⃣🏠 - 基于 .NET 9 的 C# MCP 服务器 SDK ,支持 NativeAOT ⚡ 🔌
- spring-ai-mcp ☕ 🌱 - 用于构建 MCP 客户端和服务器的 Java SDK 和 Spring Framework 集成,支持多种可插拔的传输选项
- @marimo-team/codemirror-mcp - CodeMirror 扩展,实现了用于资源提及和提示命令的模型上下文协议 (MCP)
实用工具
- boilingdata/mcp-server-and-gw 📇 - 带有示例服务器和 MCP 客户端的 MCP stdio 到 HTTP SSE 传输网关
- isaacwasserman/mcp-langchain-ts-client 📇 - 在 LangChain.js 中使用 MCP 提供的工具
- lightconetech/mcp-gateway 📇 - MCP SSE 服务器的网关演示
- mark3labs/mcphost 🏎️ - 一个 CLI 主机应用程序,使大型语言模型 (LLM) 能够通过模型上下文协议 (MCP) 与外部工具交互
- MCP-Connect 📇 - 一个小工具,使基于云的 AI 服务能够通过 HTTP/HTTPS 请求访问本地的基于 Stdio 的 MCP 服务器
- SecretiveShell/MCP-Bridge 🐍 - OpenAI 中间件代理,用于在任何现有的 OpenAI 兼容客户端中使用 MCP
- sparfenyuk/mcp-proxy 🐍 - MCP stdio 到 SSE 的传输网关
- upsonic/gpt-computer-assistant 🐍 - 用于构建垂直 AI 代理的框架
客户端
[!NOTE]
寻找 MCP 客户端?请查看 awesome-mcp-clients 仓库。
提示和技巧
官方提示关于 LLM 如何使用 MCP
想让 Claude 回答有关模型上下文协议的问题?
创建一个项目,然后将此文件添加到其中:
https://modelcontextprotocol.io/llms-full.txt
这样 Claude 就能回答关于编写 MCP 服务器及其工作原理的问题了
来源
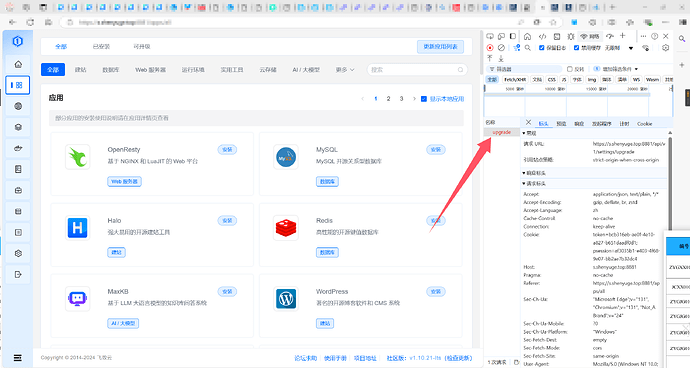
1panel|面板升级失败,请求超时!请您稍后重试
安装1panel面板后时不时提醒:请求超时!请您稍后重试
f12后发现是更新接口出现了问题
点击更新1panel会调用 /api/v1/settings/upgrade 接口,这个接口超时导致升级失败
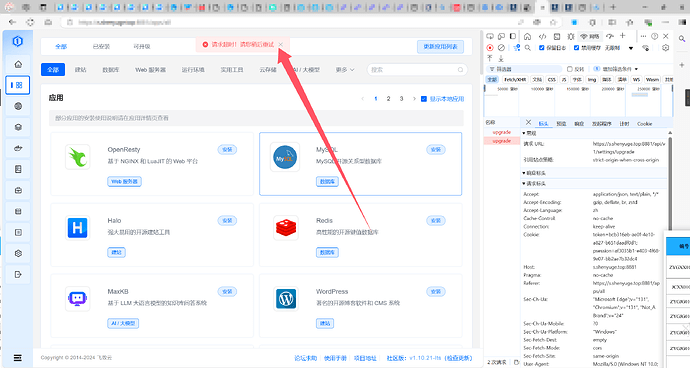
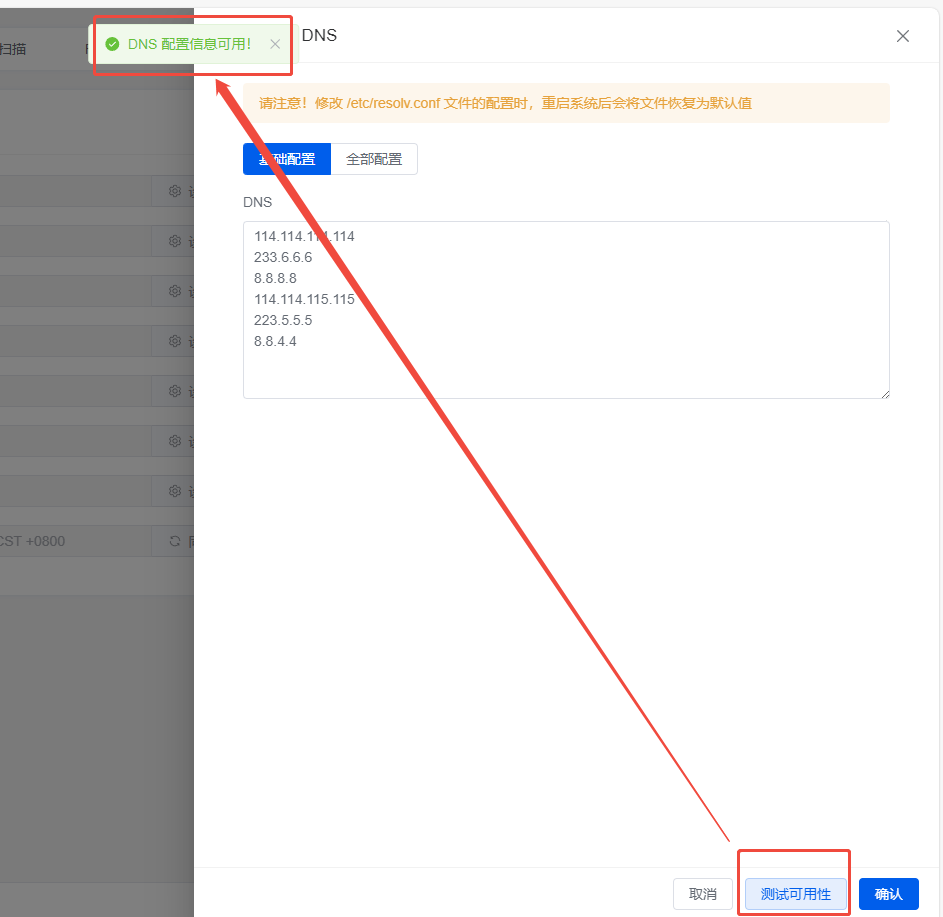
通过更换DNS解决问题: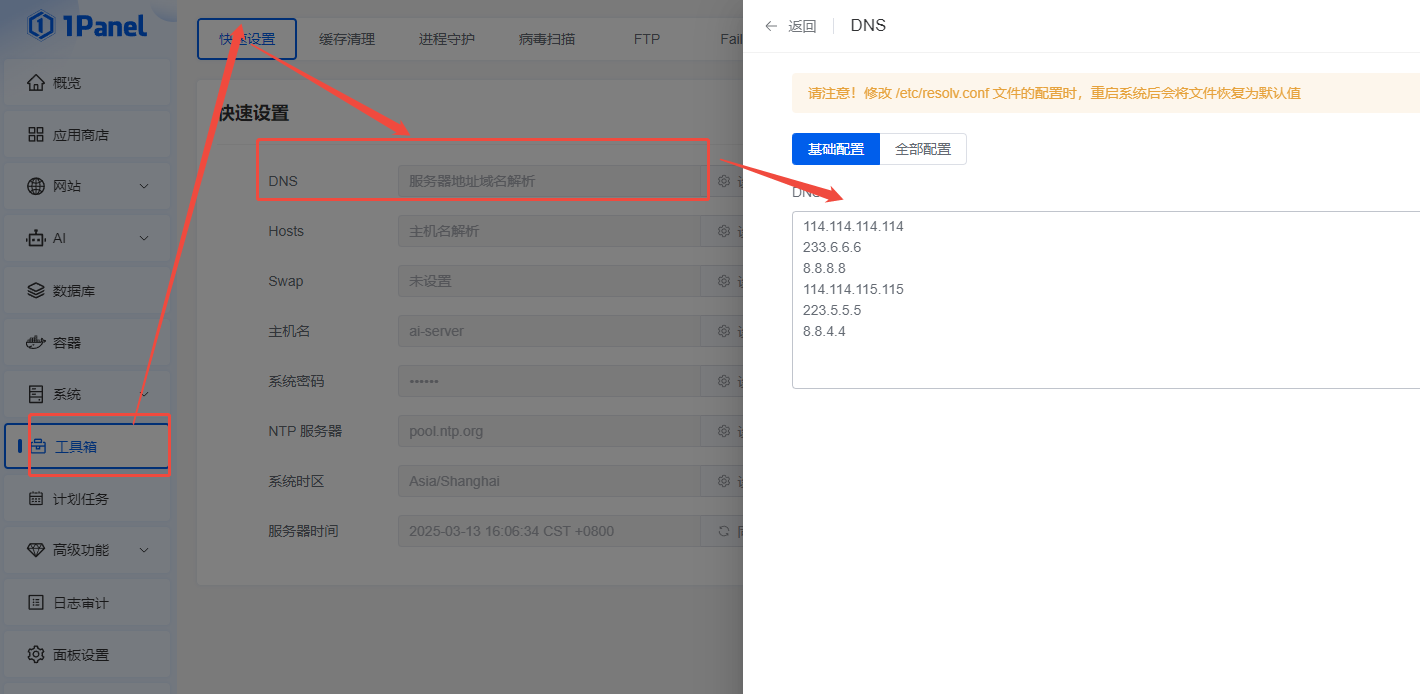
测试效果: