我非常喜欢 Claude 的 Artifacts 功能,它允许你提示 Claude 创建一个交互式的单页应用(使用 HTML、CSS 和 JavaScript),然后在 Claude 界面中直接查看结果,与机器人进一步迭代,如果你喜欢,还可以复制出生成的代码。
我翻看了我的 Claude 活动导出(我构建了一个 claude-to-sqlite 工具将其转换为 SQLite,我可以在 Datasette 中探索它),并决定看看我 在过去一周 使用了多少 artifacts。比我预想的要多!
能够启动一个完整的交互式应用程序——有时作为一个说明性的原型,但通常是直接解决问题的工具——是一个非常有用的工具。
以下是我在过去七天中使用 Claude Artifacts 的大部分内容。我为几乎所有内容提供了提示或完整记录。
- 使用 Jina Reader 将 URL 转换为 Markdown
- WASM 中的 SQLite 演示
- 提取 URL
- 剪贴板查看器
- Pyodide REPL
- 照片相机设置模拟器
- LLM 定价计算器
- YAML 到 JSON 转换器
- OpenAI 音频
- QR 码解码器
- 图像转换器和页面下载器
- HTML 实体转义器
- text-wrap-balance-nav
- ARES 语音字母转换器
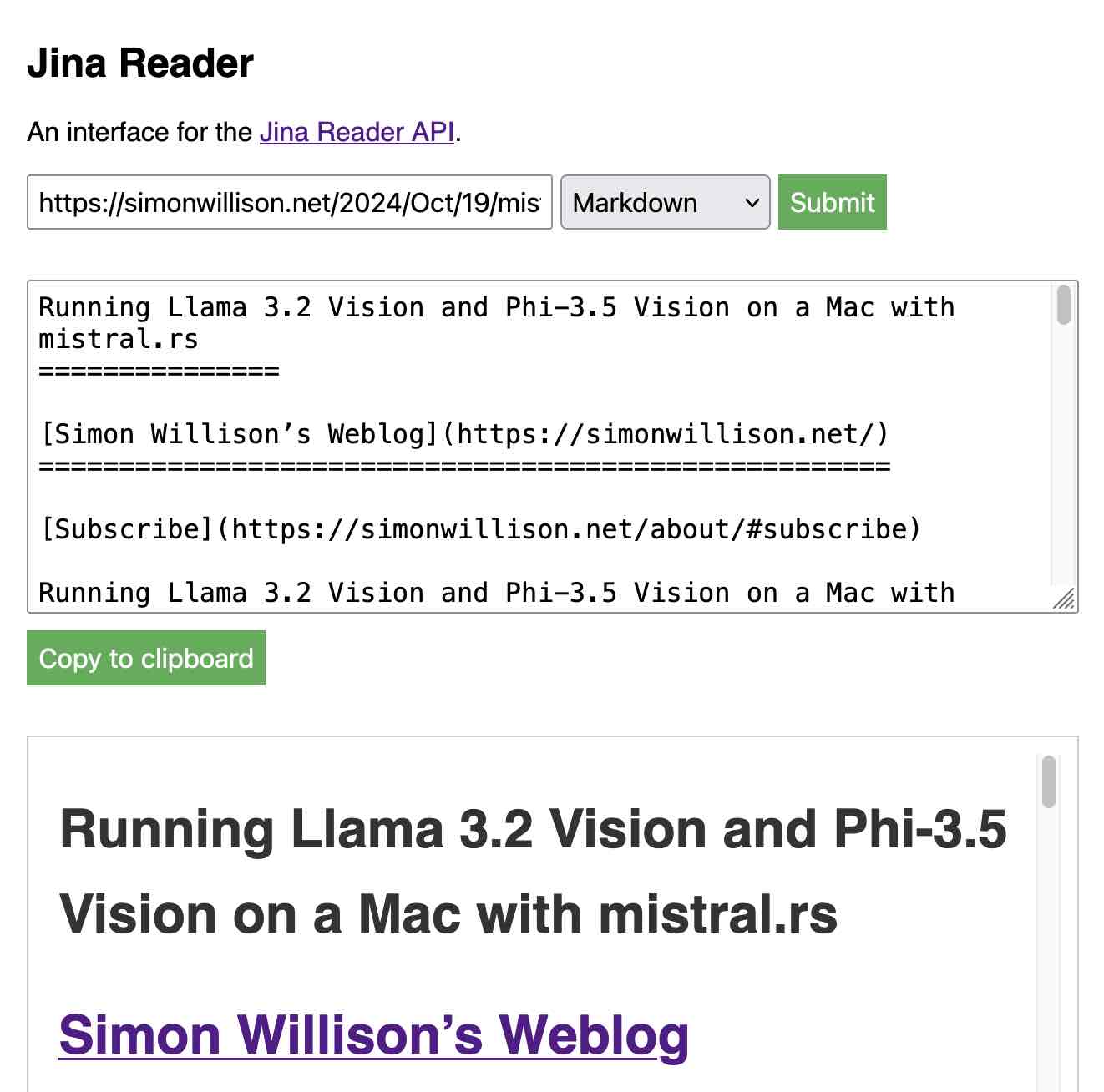
使用 Jina Reader 将 URL 转换为 Markdown #
我因为在使用移动版 Safari 时很难将整个网页的文本复制粘贴到 LLM 中而感到沮丧。所以我构建了一个简单的 Web UI,允许我输入 URL,调用 Jina Reader API 生成 Markdown(它在底层使用 Puppeteer),并为我提供带有方便的“复制”按钮的 Markdown。
试用一下:https://tools.simonwillison.net/jina-reader (代码)
WASM 中的 SQLite 演示 #
关于 SQLite 的 WASM 构建的 Hacker News 对话 引导我到 NPM 上的 @sqlite.org/sqlite-wasm 包,我决定快速拼凑一个交互式演示。
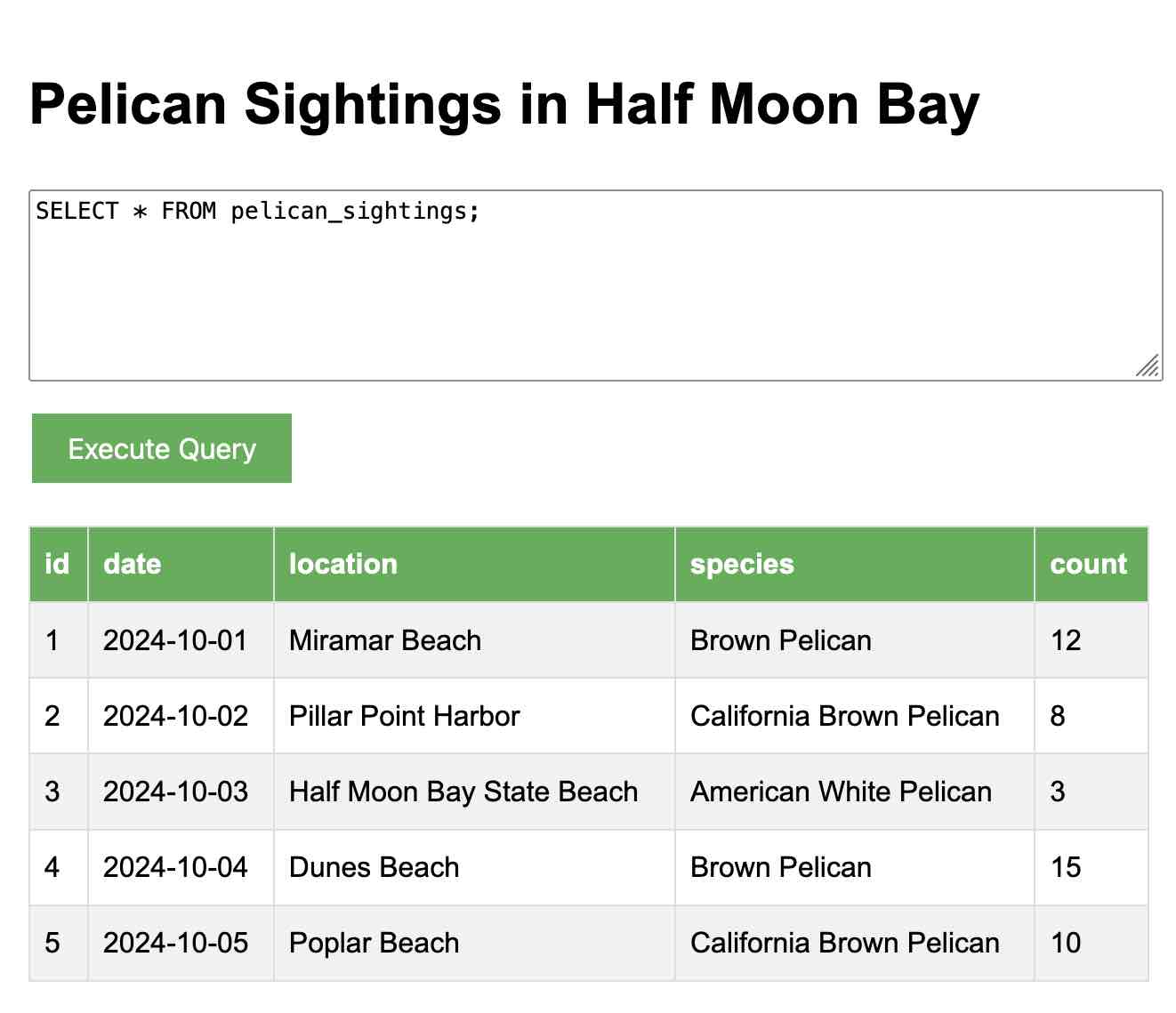
在这里试用:tools.simonwillison.net/sqlite-wasm
我发现自己想提取网页上的一段文本链接的所有底层 URL。我意识到最快的方法是启动一个可以接受富文本 HTML 粘贴并使用 HTML 解析器提取这些链接的 artifact。
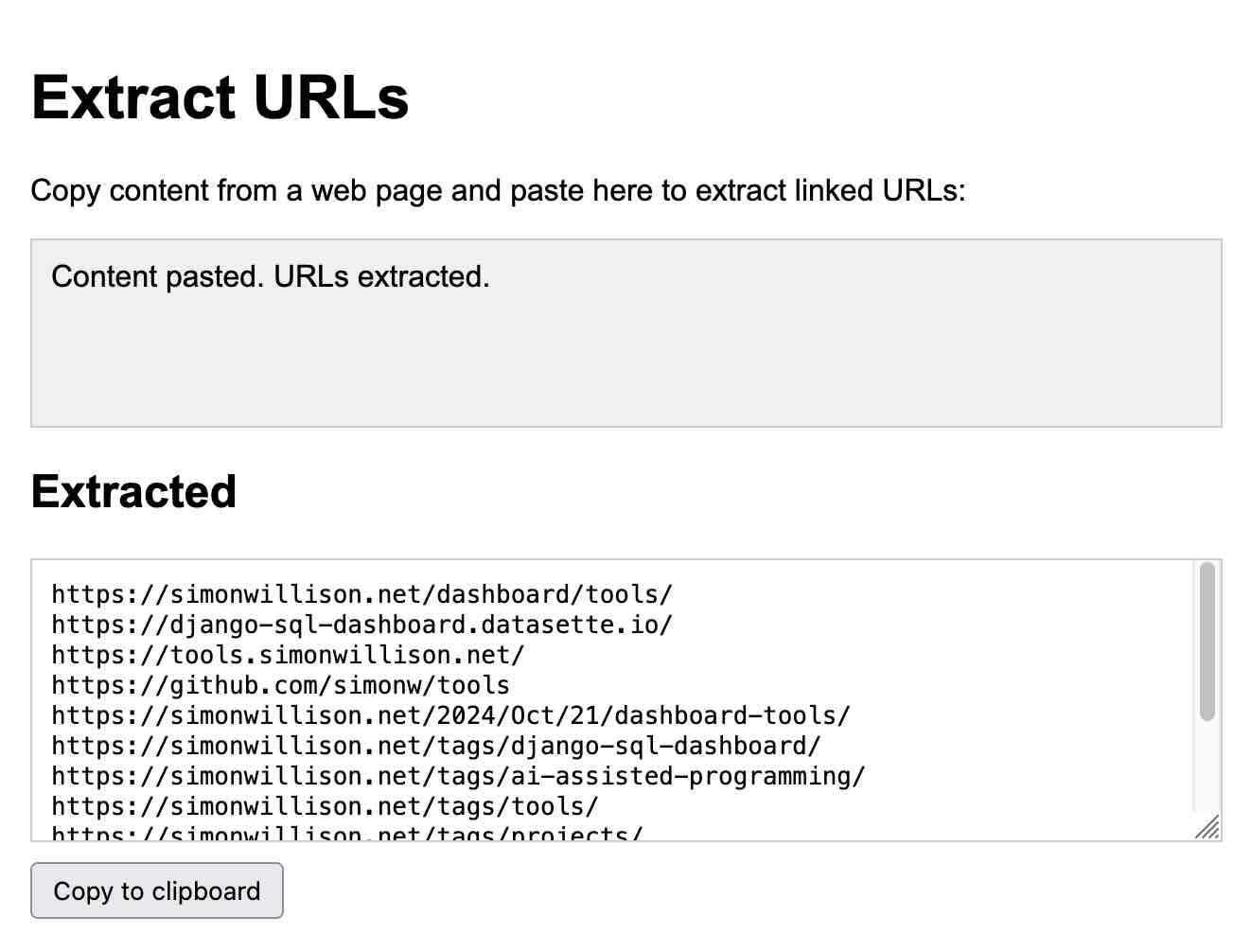
https://tools.simonwillison.net/extract-urls
剪贴板查看器 #
摆弄一个允许你粘贴富文本的工具让我想起了浏览器剪贴板 API 是一件令人着迷的事情。我决定构建一个快速调试工具,让我可以复制和粘贴不同类型的内容(纯文本、富文本、文件、图像等),并查看浏览器中可用的信息。
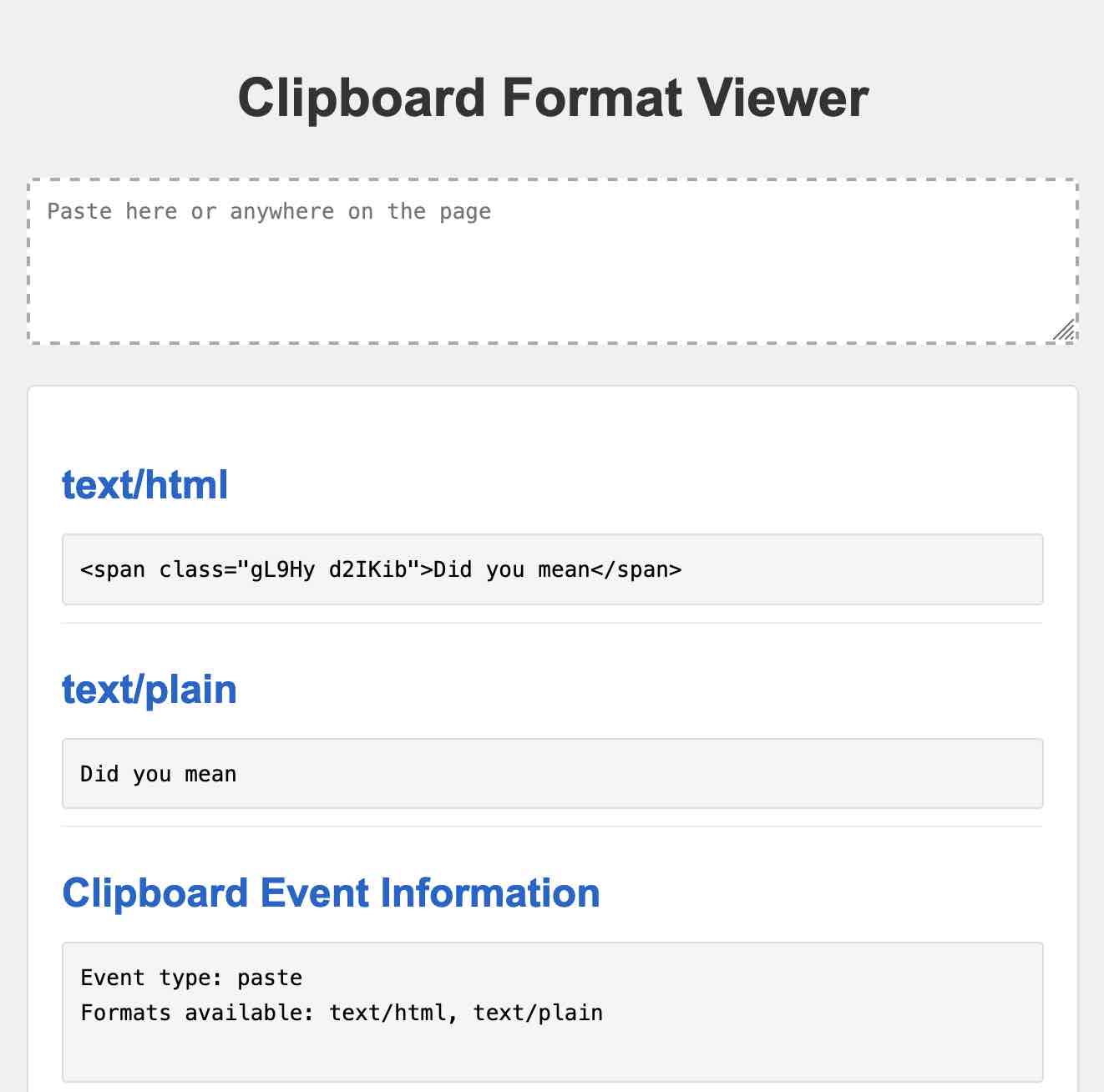
https://tools.simonwillison.net/clipboard-viewer
Pyodide REPL #
我没有在这个上面花太多精力。在浏览器 DevTools 中摆弄 Claude Artifacts 时,我发现了这个 CSP 标头:
content-security-policy: default-src https://www.claudeusercontent.com; script-src 'unsafe-eval' 'unsafe-inline' https://www.claudeusercontent.com https://cdnjs.cloudflare.com https://cdn.jsdelivr.net/pyodide/; connect-src https://cdn.jsdelivr.net/pyodide/; worker-src https://www.claudeusercontent.com blob:; style-src 'unsafe-inline' https://www.claudeusercontent.com https://cdnjs.cloudflare.com https://fonts.googleapis.com; img-src blob: data: https://www.claudeusercontent.com; font-src data: https://www.claudeusercontent.com; object-src 'none'; base-uri https://www.claudeusercontent.com; form-action https://www.claudeusercontent.com; frame-ancestors https://www.claudeusercontent.com https://claude.ai https://preview.claude.ai https://claude.site https://feedback.anthropic.com; upgrade-insecure-requests; block-all-mixed-content
其中的 https://cdn.jsdelivr.net/pyodide/ 引起了我的注意,因为它表明 Anthropic 开发团队故意设置它,以便可以将 Pyodide(编译为 WebAssembly 的 Python)加载到 artifact 中。
我让 Claude 启动了一个非常快速的演示来证明这一点:
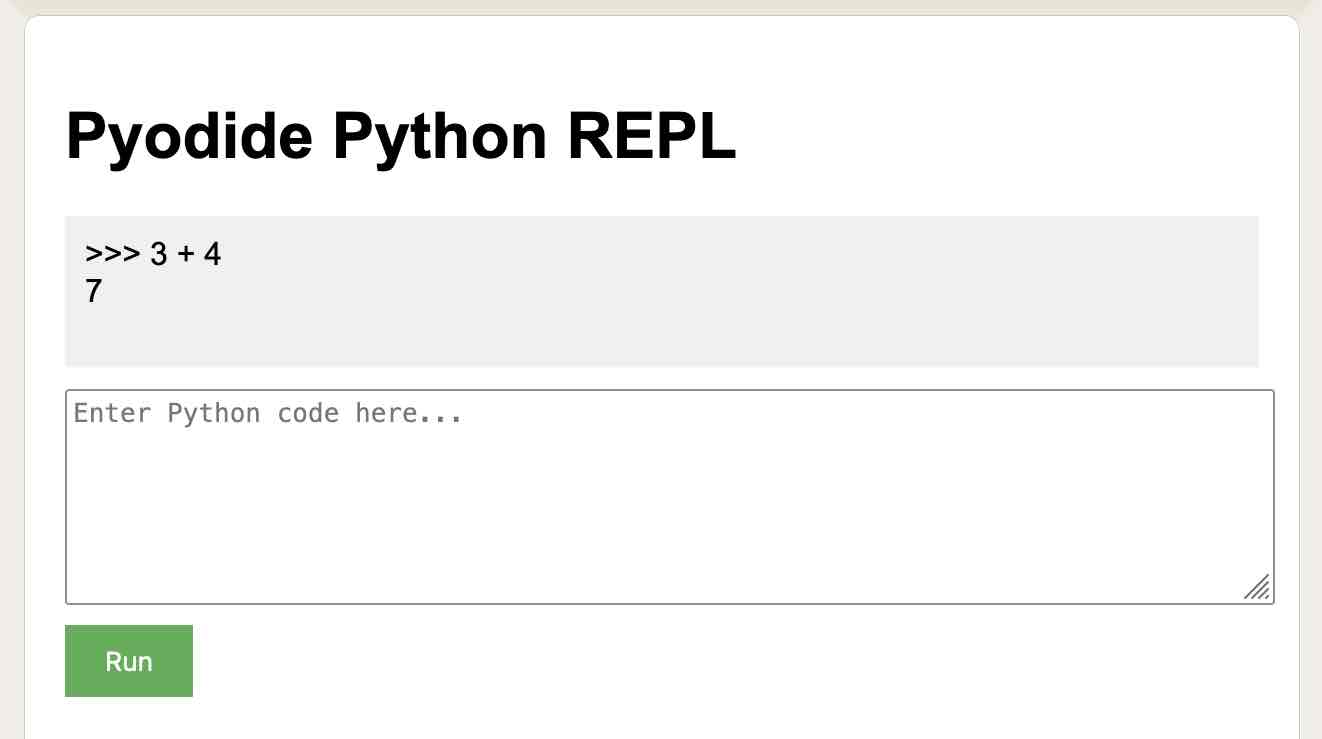
https://claude.site/artifacts/a3f85567-0afc-4854-b3d3-3746dd1a37f2
我还没有费心将这个提取到我自己的 tools.simonwillison.net 站点,因为它纯粹是一个概念证明,证明 Pyodide 可以在该环境中正确加载。
照片相机设置模拟器 #
我外出拍照散步,并好奇 JavaScript 是否可以提供相机设置的模拟。我没有在这个上面走太远(在海滩散步时在手机上提示)——结果有错误且令人印象不快,我很快就失去了兴趣。不过,它让我接触到了用于操作 canvas 元素的 Fabric.js 库。
https://claude.site/artifacts/e645c231-8c13-4374-bb7d-271c8dd73825
LLM 定价计算器 #
这个我 确实 完成了。我构建了这个定价计算器,作为我使用 Google Gemini 进行视频抓取 的实验的一部分,因为我不相信自己对 Gemini 有多便宜的计算!这里有关于我如何构建它的详细说明。
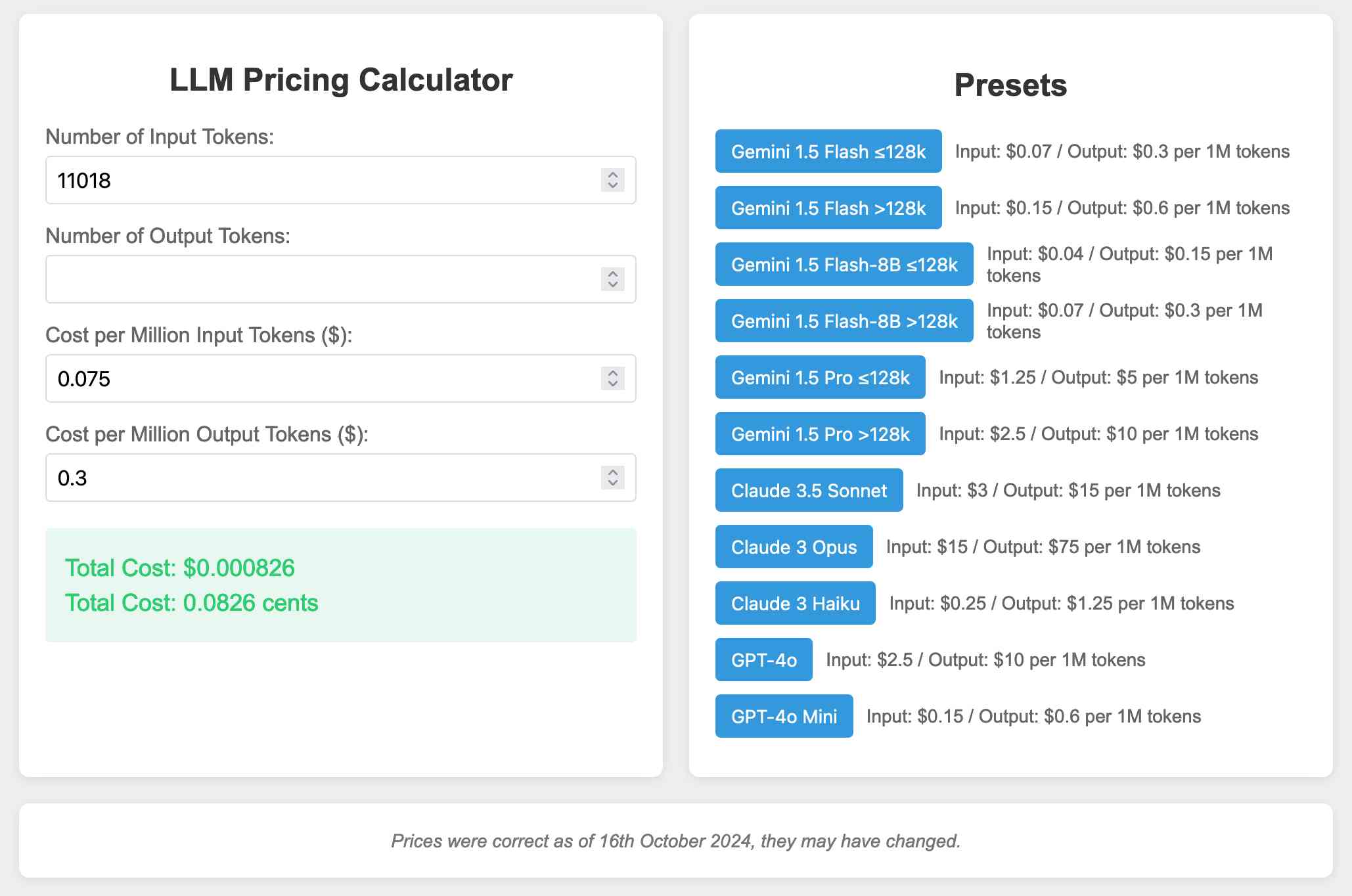
https://tools.simonwillison.net/llm-prices
YAML 到 JSON 转换器 #
我想提醒自己 YAML 语法的某些方面是如何工作的,所以我启动了一个快速的 YAML 到 JSON 转换器工具,该工具在您键入 YAML 时实时显示等效的 JSON。

https://claude.site/artifacts/ffeb439c-fc95-428a-9224-434f5f968d51
OpenAI 音频 #
这是我本周最有趣的 artifact。我正在探索 OpenAI 的新音频 API,并决定看看是否可以让 Claude 构建一个网页,该网页可以请求访问我的麦克风,录制一段音频,然后对其进行 base64 编码并将其发送到 OpenAI API。
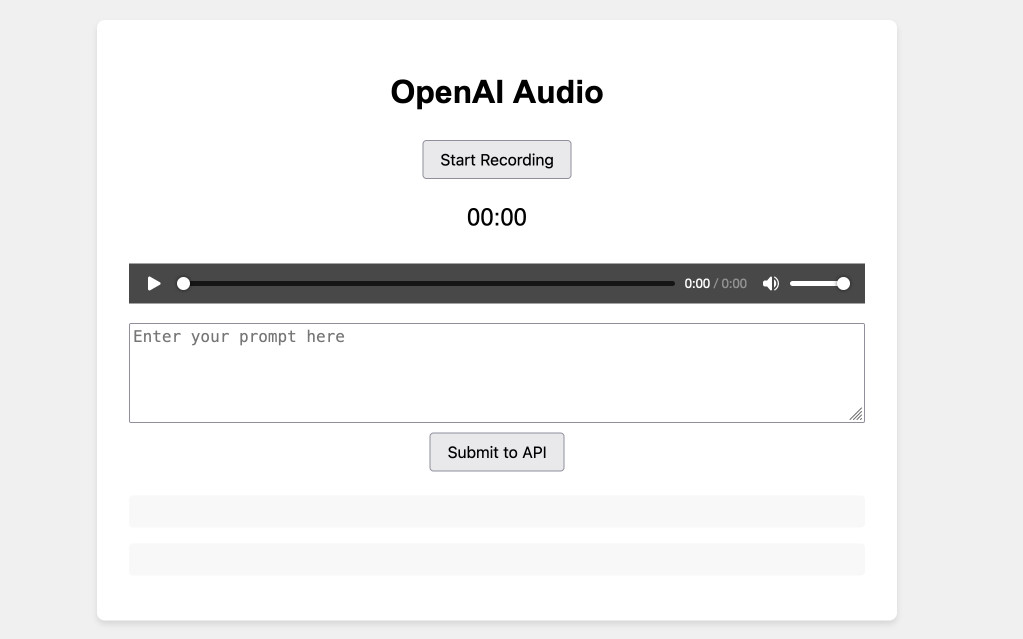
https://tools.simonwillison.net/openai-audio
Claude Artifacts 不能直接向外部主机发出 API 请求,但它仍然可以启动足够多的工作版本,以便很容易地将其移动到不同的托管并完成工作。
我在构建一个工具,展示 Gemini Pro 如何返回图像中对象的边界框 中撰写了更多关于此 API 模式的内容。
QR 码解码器 #
本周早些时候,我参加了一个会议,其中一位参与者分享了一张带有 QR 码的幻灯片(用于加入实时调查工具)。我没有带手机,所以我需要一种将 QR 码转换为常规 URL 的方法。

https://tools.simonwillison.net/qr
在 Claude Artifacts 中敲定这个 QR 解码器只花了几秒钟:
构建一个 artifact(没有 react),让我可以粘贴 QR 码并显示解码后的信息,并在必要时显示超链接
[ … ]
有一个文件打开框,也可以让你拖放,并在页面上添加一个 onpaste 处理程序,以捕获粘贴的图像
图像转换器和页面下载器 #
另一个非常快速的原型。在 Hacker News 上,有人演示了一个巧妙的工具,该工具允许您将照片拖放到页面上,并将其作为 base64 URL 烘焙到页面中,这样您就可以“另存为 HTML”并获得一个包含图库的自包含页面。
我建议他们可以添加 一个生成带有烘焙的新页面的“下载链接”的功能——在不允许您“另存为 HTML”的移动电话上很有用——并让 Claude 敲定一个快速原型:
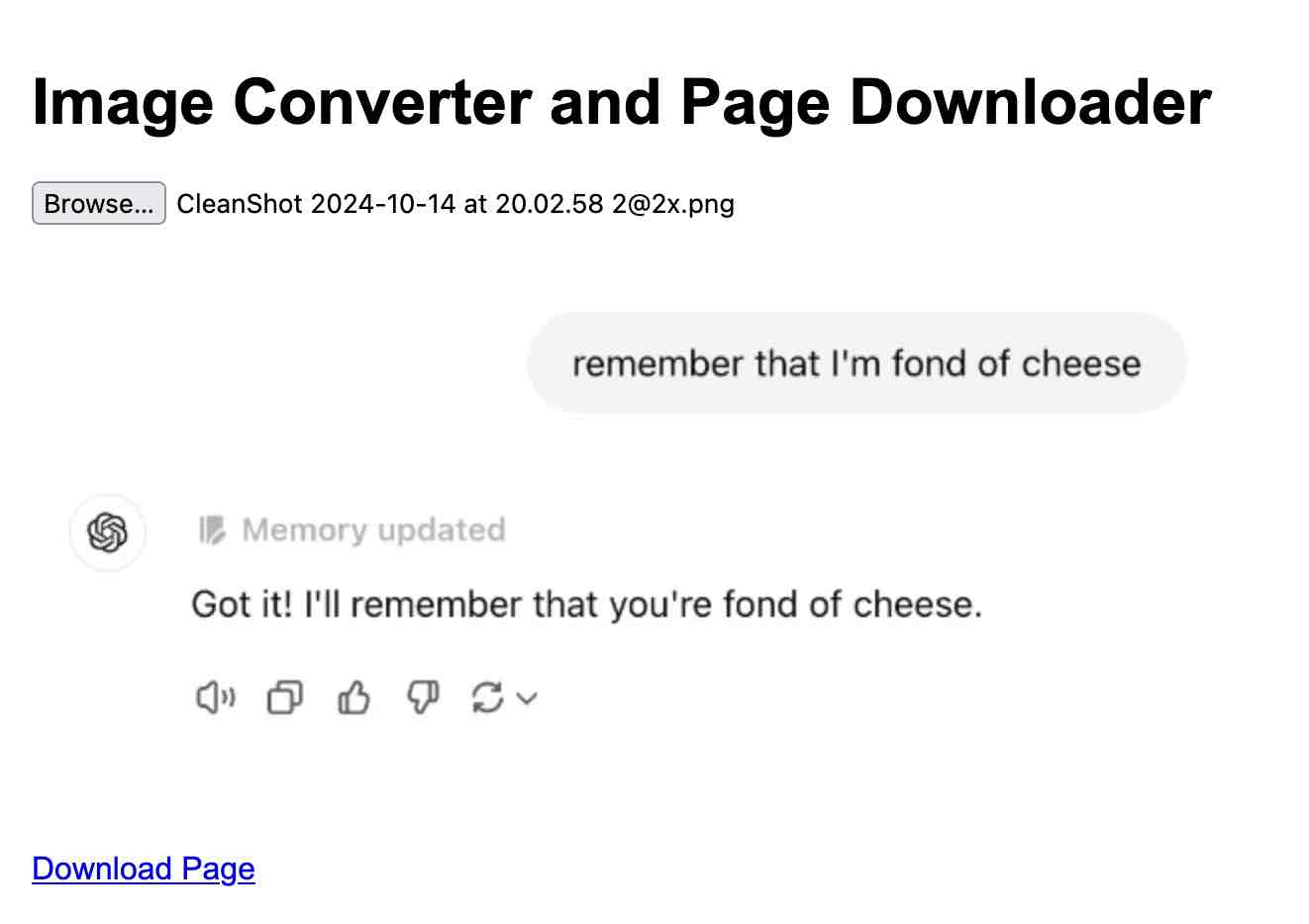
在这种情况下,我在 Gist 中共享了代码,然后使用我新接触的 https://gistpreview.github.io/?GIST_ID_GOES_HERE 技巧来渲染结果:
https://gistpreview.github.io/?14a2c3ef508839f26377707dbf5dd329
事实证明,gistpreview 是将 LLM 生成的演示转换为人们可以查看的页面的非常快捷的方式。
HTML 实体转义器 #
按需软件的另一个示例:我需要在手机上的一段文本中转义 HTML 实体,所以我让 Claude 为我构建了一个工具:
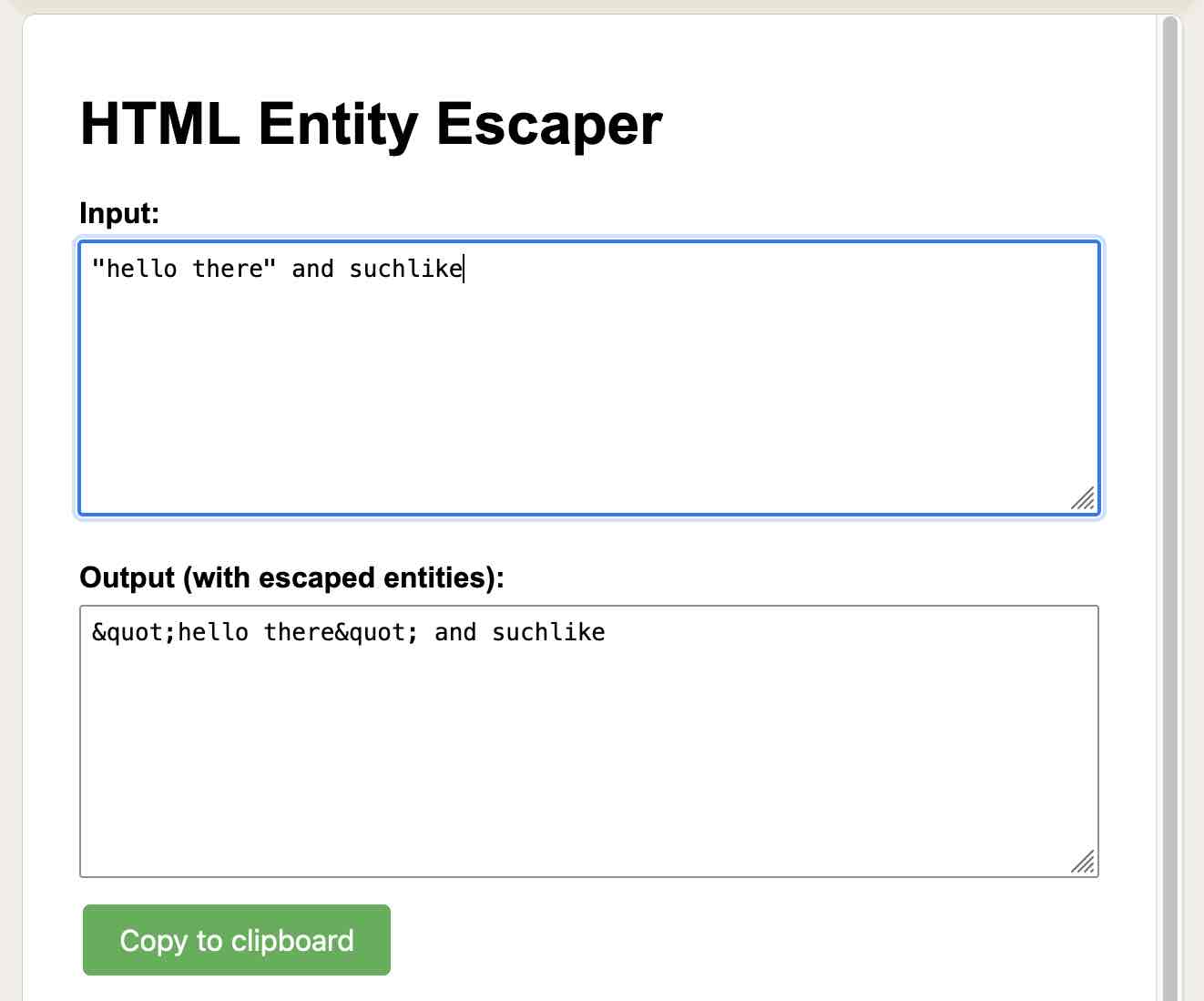
https://claude.site/artifacts/46897436-e06e-4ccc-b8f4-3df90c47f9bc
这是我使用的提示:
构建一个 artifact(没有 react),我可以在其中将文本粘贴到文本区域中,它将返回该文本,其中所有 HTML 实体——单引号和双引号以及小于号、大于号和 & 符号——都已正确转义。输出应在文本区域中,并附带一个“复制到剪贴板”按钮,该按钮在您单击后 1.5 秒内将文本更改为“已复制!”。使其适合移动设备
text-wrap-balance-nav #
受 Terence Eden 的启发,我决定对 text-wrap: balance CSS 属性进行快速实验。我让 Claude 为我构建了一个带有滑块和复选框的示例导航栏。我在这里写了关于它的内容。
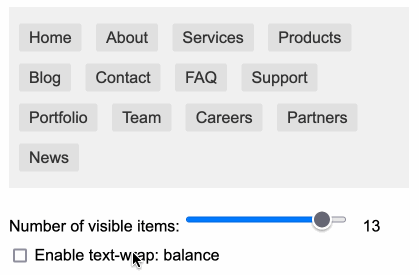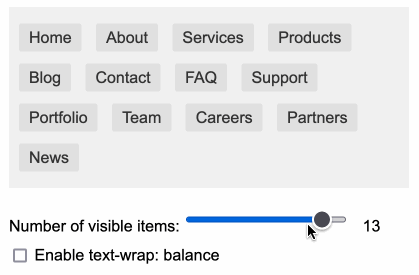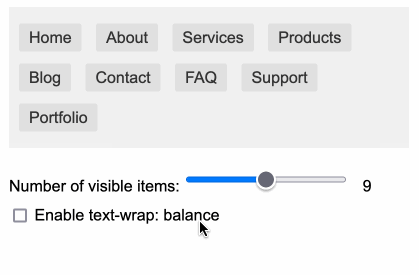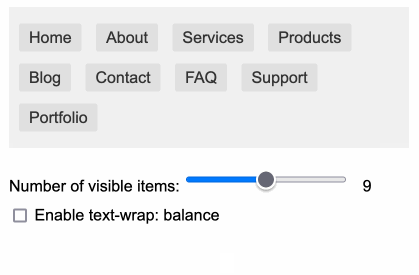
https://tools.simonwillison.net/text-wrap-balance-nav
ARES 语音字母转换器 #
我作为 半月湾南瓜跑 的业余无线电通信操作员做志愿者,并且担心我会弄乱使用语音字母——所以我让 Claude 构建了这个工具:
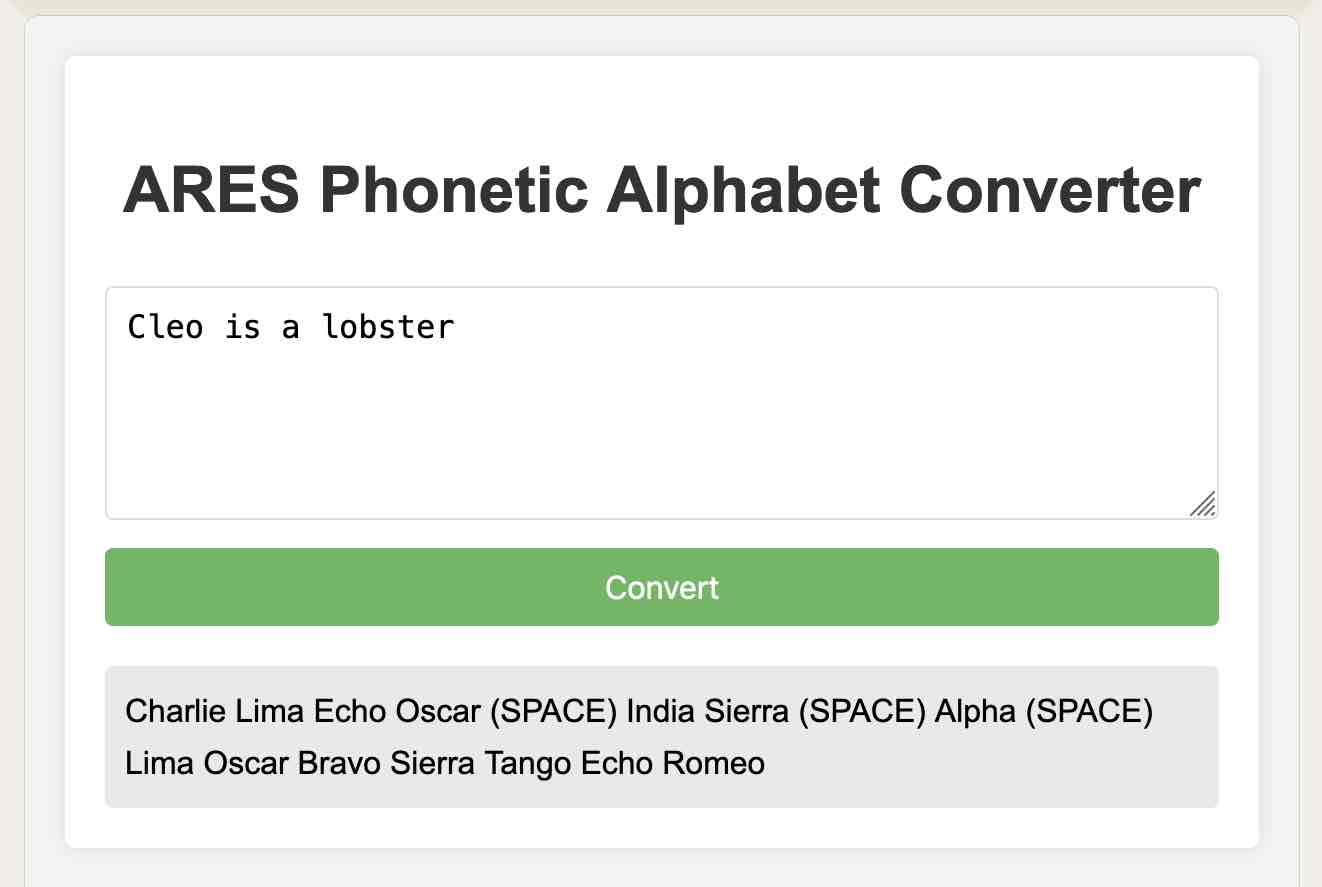
https://claude.site/artifacts/aaadab20-968a-4291-8ce9-6435f6d53f4c
Claude 记录在这里。有趣的是,它首先用 Python 构建了它,然后在我提醒它我想要“一个交互式 Web 应用程序”后切换到 JavaScript。
这太有用了,而且非常有趣! #
正如你所看到的,我是这个功能的 重度 用户——我刚刚描述了在一个星期内产生的 14 个项目。我从 6 月 20 日(与出色的 Claude 3.5 Sonnet 一起发布,它仍然是我的日常 LLM)开始使用 artifacts,现在我每天都会启动一个新的交互式 artifact 几次。
我正在使用 artifacts 进行闲暇的好奇心、快速原型设计、库研究和启动解决当前问题的工具。
这些工具中的大多数都花了不到五分钟的时间来构建。一些更复杂的工具花费的时间更长,但即使是 OpenAI Audio 工具,第一个版本也花费了 上午 11:55 到下午 12:07,第二个版本花费了 下午 12:18 到下午 12:27——总共 21 分钟。
请查看我的 claude-artifacts 标签,以获取更多示例,包括 SVG 到 JPG/PNG、Markdown 和 Math Live Renderer 和 图像调整大小和质量比较。
我还有一个链接到我的 tools.simonwillison.net 站点的每个帖子的仪表板,以及底层的 simonw/tools GitHub 存储库,其中包含更多未列出的工具,其中大多数工具在其提交历史记录中链接到它们的 Claude 对话记录。
我开始对它们的局限性感到有点沮丧——特别是 artifacts 无法发出 API 调用、提交表单甚至链接到其他页面的方式。我可能会最终根据我迄今为止学到的关于它们的所有知识,启动我自己的小型 artifacts 替代方案。
如果你 没有 使用 artifacts,我希望我已经让你了解了为什么它们是我目前最喜欢的基于 LLM 的工具之一。






